Contexte
Dans le cadre de mes obligations de veille technologique, j'ai cherché à mettre en place une solution permettant de rester informé des évolutions du secteur informatique de manière régulière et structurée. Dans un premier temps, j'ai utilisé Feedly comme agrégateur de flux RSS, ce qui m'a permis d'identifier les sources pertinentes et d'adopter une routine de consultation quotidienne.
Face aux limites de cette approche manuelle (volume d'articles important, risques de redondance, temps de lecture élevé) j'ai pris l'initiative de concevoir et de déployer un pipeline d'automatisation capable de filtrer, analyser et me transmettre uniquement les informations à réelle valeur ajoutée.
Objectifs de la mission
L'objectif central était de réduire le bruit informationnel en automatisant la chaîne de traitement des articles issus de flux RSS, depuis leur réception jusqu'à leur livraison sous forme de résumé exploitable, tout en évitant les doublons et en écartant les contenus non pertinents.
Réalisations techniques Ma mission s'est articulée autour de plusieurs axes majeurs :
- Conception du pipeline d'automatisation avec Make
- Intégration d'un double filtrage par IA (GPT)
- Historisation et gestion des données avec Airtable
Livraison des résumés par e-mail via Gmail
Fonctionnalités développées
- Vérification de la redondance thématique (l'article a-t-il déjà été traité ?)
- Tri intelligent par IA avec exclusion des annonces et contenus commerciaux
- Résumé automatique des articles retenus
- Historisation complète des flux reçus et traités dans Airtable
Détail du scénario Make
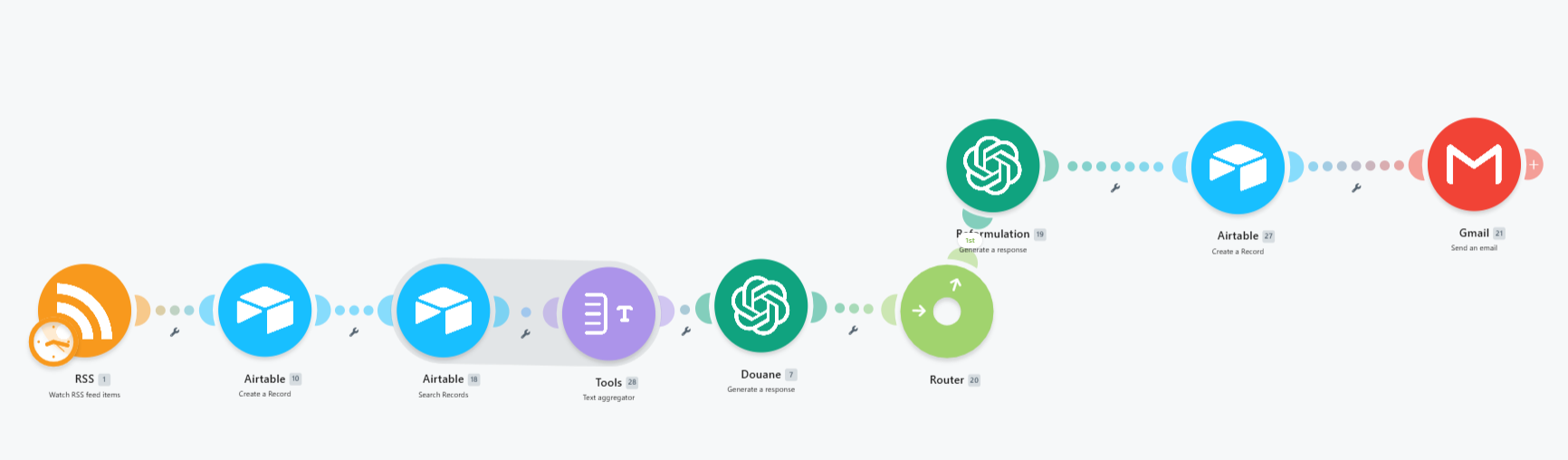
Le scénario repose sur la chaîne suivante :
RSS → Airtable (Flux reçu) → Airtable Search (Flux traité) → Text Aggregator → OpenAI "Douane" → Router → OpenAI "Reformulation" → Airtable (Flux traité) → Gmail
- Collecte RSS : Le module surveille les flux RSS configurés et déclenche le scénario à chaque nouvel article détecté.
- Enregistrement dans "Flux reçu" : Chaque article entrant est immédiatement enregistré dans une première table Airtable, servant de journal de bord.
- Recherche dans "Flux traité" : Une recherche est effectuée dans la seconde table pour récupérer les articles récemment traités, triés par date de création décroissante. Ce contexte est compilé via un Text Aggregator.
- Module "Douane" (OpenAI) : Un premier appel à l'IA compare le nouvel article avec l'historique des articles déjà traités. L'IA décide si l'article apporte une information nouvelle (réponse OUI) ou non (réponse NON). Ce module assure également l'exclusion des contenus à caractère commercial ou promotionnel.
- Routeur : En fonction de la réponse de la Douane, le flux est soit stoppé, soit transmis à l'étape suivante.
- Module "Reformulation" (OpenAI) : Un second appel à l'IA génère un résumé structuré de l'article, prêt à être consommé.
- Archivage dans "Flux traité" et envoi par e-mail via Gmail.
État d'avancement
Le scénario est fonctionnel dans son ensemble : les résumés sont générés et les e-mails sont bien envoyés. Un problème de gestion des doublons est encore en cours de résolution (l'ordre des étapes de création et de recherche dans Airtable fait l'objet d'un ajustement). Ce projet illustre avant tout une démarche d'initiative personnelle visant à répondre concrètement à un besoin identifié.
Compétences valorisées
Bloc 1 – La compétence centrale
- Organiser son développement professionnel — c'est la compétence directement visée par la veille technologique. Elle va ici bien au-delà de la simple consultation de Feedly : l'initiative d'automatiser la chaîne de traitement pour maintenir une veille fiable et continue en démontre une appropriation active et réfléchie.
Bloc 1 – Compétences transversales
- Travailler en mode projet — conception du pipeline, choix des outils, itérations successives pour améliorer la fiabilité (gestion des doublons, logique de filtrage), et documentation de la démarche.
Bloc 2 – SLAM (Ouverture)
- Gérer les données — structuration en deux tables Airtable distinctes (Flux reçu / Flux traité), logique de recherche et de comparaison pour éviter la redondance, gestion du cycle de vie des données traitées.
- Concevoir et développer une solution applicative — le pipeline Make constitue une véritable solution applicative d'automatisation : modélisation du flux de traitement, intégration de plusieurs API (OpenAI, Airtable, Gmail), gestion des branchements conditionnels via le routeur.
Schéma d'infrastructure